
In a previous article titled A Methodology for a Transparent and Traceable Solution Architecture, I outlined a methodology an architect can use to create a transparent and traceable solution architecture. This article will expand on that and will use a real world example of business requirements to derive a solution architecture going from requirements to the end logical solution while accounting for the most important steps to ensure we have a transparent process, end up with traceable results, and have adequately documented target state artifacts. A set of business requirements can be defined and presented in different ways, but for the purposes of this article, we’ll use a set of business requirements that you might see expressed as part of a business requirement document (BRD) as an example that sets the business context of the problem the solution architecture is going to allow us to solve. Let’s dig into these example business requirements, and let’s break that out into a set of decisions that will form the resulting architecture based on the requirements, constraints, and risks. This article is written as a story using the example herein and follows the journey of a solution architect from requirements to architecture.
Business Requirements
- Upon order by a client, a sales invoice is to be created in the correct financial system
- 1.1 Invoice needs to be coded to the proper GL account in the financial system
- 1.2 There are multiple financial systems in the global organization and the payment confirmation needs to be routed to the correct system
- Upon successful client payment, a payment confirmation will need to be created in the correct financial system
- 2.1 Payment confirmation needs to be coded to the proper GL account in the financial system
- 2.2 There are multiple financial systems in the global organization and the payment confirmation needs to be routed to the correct system
These are relatively simple business requirements suitable for this example, but as we dig into them, we start to unravel complexities and get clarifications that will have an impact on the resulting architecture and add new complexity to the process.
Requirements Investigation, Clarifications, and Conversations with the Business and Business Analysts
The first step, generally, is to get clarifications on the business requirements which usually entail deep dives, multiple rounds of communication with business teams, and deep dives in meetings. This article won’t go in depth into the clarification process, and will assume clarifications have been made to a level that is satisfactory to the solution architect and that there is alignment on those clarifications. As we proceed to review these clarifications as per the example business requirements provided, the following observations are documented and further validated:
- There are three different financial systems across the organization that handle finance for three of the organizations legal entities. The scope of this solution only includes two of them.
- The source application from the vendor is called “ProSass” (this is a fictional name depicted for the purposes of this article and examples) and the client (the organization) will receive confirmation of payments made by customers. The source application handles all the payment transactions on behalf of the organization.
- The source application does not know anything about the GL accounts used in the financial systems
- Depending on the category of the invoice and payment, the GL account is coded differently, and furthermore each financial system has it’s own differing set of GL accounts
- A payment confirmation from the “ProSass” SaaS application indicates the money was successfully transferred from the customer to the organization’s bank
- The financial systems do not know anything about the categories used in the source SaaS application
- The customer ID’s used in the SaaS source system match the customer IDs used in the financial system. There was an exercise done by the business earlier this year to ensure a consistent customer ID used across the enterprise to identify a single paying customer entity.
As we clarify the requirements, we build and document a body of knowledge which starts to capture information that is not obvious or clear just by looking at the requirements. It’s important that as the body of knowledge is documented that it is made available to ensure continual team and stakeholder alignment.
System Context
It’s crucial to have a solid understanding of the entire context of the system, and in this case, this includes the financial systems that form part of this solution, the vendor’s “ProSass” SaaS application, the current business processes, and a complete picture of the current state. Any missing documentation, such as a lack of current state architecture artifacts should be addressed here, and suitable artifacts should be created, if necessary, such as a current state solution architecture which helps ensure that the current state is properly assessed within the context of the future state. Intelligence gathering and reviewing existing architecture for these systems is important here as well as understanding their place on technology roadmaps and any upgrades or “change freeze” times on these systems that may impact delivery of your solution. As a result of these types of exercises, in our example, we identify the following facts:
- There are two different financial systems used within the context of the solution:
- PeopleSoft Financials, Microsoft Great Plains
- There are no plans or business support to consolidate these into a single system for both entities
- The organization’s PeopleSoft Financials instance has a standard way to ingest data: A new table is built for each case, and data has to be written to that table followed by a new job that imports the data into the PeopleSoft tables. This is the standard and there is no appetite or necessity to change this ingestion process.
- Microsoft Great Plains has a native SOAP based web service, but to date there are no integrations to it. It has been identified that these integrations as part of this solution will be the first to be implemented.
The ProSass (SaaS) application that is the source of this data is a relatively new application, and it is currently already running in production and the organization has procured it within a single tenant environment. The SaaS application is being provided and maintained by a vendor, and because the payment functionality is a new feature they have built into the system they are giving an opportunity to the you (and the organization) to influence the technical direction of the API or service interface that the vendor will use to provide consumption capabilities for the data. As the solution architect, you now have the opportunity to influence the vendor to ensure they build and provide a suitable and modern interface.
Different interface architectures for the vendor’s “ProSass” SaaS application were evaluated and discussed with the vendor, including, push vs pull models, event based architectures, and so forth. Ultimately, a feasible solution is agreed upon with the vendor which includes a comprehensive and secure REST API for consumption, and an event based messaging pattern using AMQP 1.0 (advanced message queueing protocol) to provide real time integration, including, invoice and payment events. This is great achievement, and a win-win for the organization and the vendor as the API interface architecture built into many of the SaaS applications in existence are archaic and don’t provide true real time integration.
Conceptual Architecture
At some point in between the initial requirements, information gathering and clarifications, you will have enough information to start building out a conceptual architecture. The conceptual architecture is useful in conveying to the stakeholders the approach to the solution. The earlier you build out the conceptual architecture the less accurate it may be, but early renditions are an important tool to evaluate options and solicit feedback. Conceptual architecture is also a suitable starting point when preparing reviews and presentations with non technical stakeholders and sponsors who may not understand, or care, about the technical complexity found in more detailed versions of architecture artifacts. The conceptual architecture, once mature enough, is used in part to form the basis and context of the future logical solution architecture. Although the conceptual architecture may not be detailed, it should be used to get alignment very early with the stakeholders and to resolve and address any concerns with that alignment. Correcting course earlier is always better, and the conceptual architecture allows you to get early alignment on the general direction and roadmap of the solution and correct course as early as possible.
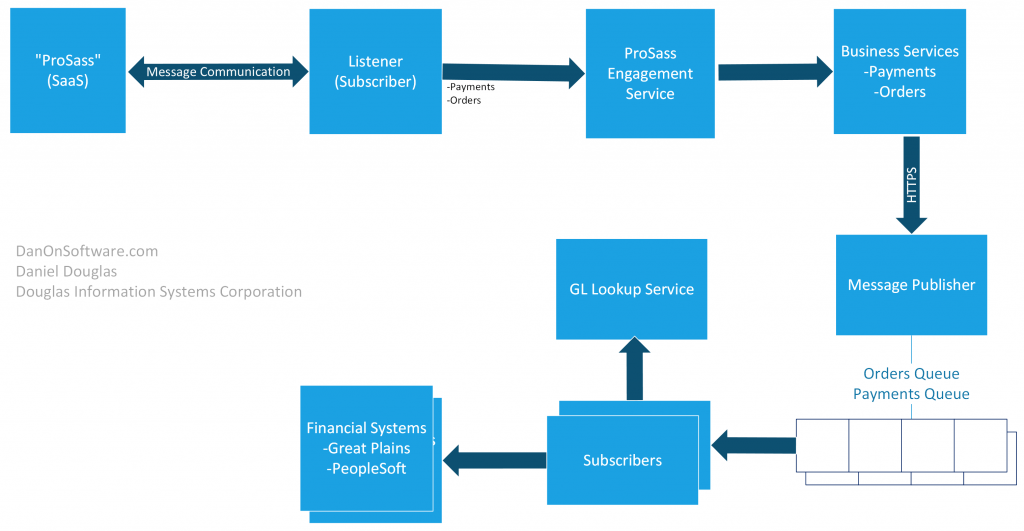
Non-Functional Requirements
Through exploratory sessions with the business and other facets of the organization, information about data classification, data load and volume, business process criticality and impact assessments are explored and documented. In our sample scenario, we end up with the following agreed upon facts:
- The business does not need the invoice or payment confirmation in real time but real time would be better. The business need is to have the data in the financial system the following day.
- In the case of disaster, the business can absorb 5 days of downtime before it has an impact on their operations.
- There is no PII (Personally Identifiable Information) contained within the scope of the solution.
- European GDPR does not apply to this solution.
- There is no credit card information or other banking information (accounts, etc) included in the payload
- Because the data includes payment amounts relating to business sensitive transactions linked to line items, the data is considered to be confidential data and encryption is required throughout the solution in-flight and at-rest.
- Payload size is on average 1k per transaction with 1000 transactions a day growing by 10% annually
Based on information gathered relating to non-functional requirements, the following statements can be made, and the evidence backing up these statements can be archived:
- Real time integrations are aligned with organizational roadmaps and standards. There is no advantage to a slower, old fashioned, batch job approach.
- The solution will be deployed into two data centres in a passive/active configuration for disaster recovery with an RTO (recovery time objective) of 72 hours and RPO (recovery point objective) of 24 hours. The RTO objective is prioritized along with systems of similar criticality across the organization.
- AES 256 and TLS 1.2 encryption is required
- The total payload is reasonable and can be absorbed with the organizations standard server infrastructure. New servers will need to be procured, and performance testing will be done to ensure performance of the solution.
Not all elements of the non-functional requirements will be indicated on the upcoming logical solution architecture such as the disaster recovery requirements which are better suited to be included as part of a physical or infrastructure diagram for the solution.
Turning Business Requirements Into Architecture
Throughout this process, no-doubt, there has been significant effort put into the significant decisions that will constitute the architecture and take into account all of the requirements that have been gathered and agreed to. There are various ways to document the architecture of a solution, but solution architecture diagrams at various levels of detail are crucial; we’ll also take all of the requirements and ensure that we adequately map them to solution architecture. Different views of the architecture are crucial here in documenting how the architecture meets both functional and non-functional requirements.
Creating the architecture is an evolving process and the architecture evolves with the requirements and clarifications of those requirements. At this point in our example scenario, we have adequate requirements, clarifications of those requirements, and we have dug deep into the non-functional requirements. We’re ready to put together a complete picture based on what we know to be true. We had early-on alignment on the conceptual architecture which set the stage for the full solution, and we are confident that all of the requirements that impact the significant architectural decisions required are known and any new information or minor changes to the requirements can be absorbed by the initial architecture without significant cost.
Let’s move forward and consider the business requirements and the clarifications we have used in our example and start creating and documenting the logical solution architecture.
We have identified the two target on-premise systems and the requirement for a real time integration to push data into those systems; we need to ensure these systems are capable of ingesting the required data. Based on what we know, we can make the following high level architectural decisions and categorize these decisions into four distinct sections:
- Data Ingress from the vendor’s “ProSass” SaaS Solution into the organization’s ecosystem
- New custom built JAVA based listener built on Rabbit MQ to listen to new message events from the vendor’s “ProSass” solution over AMQP. Following an evaluation of the organizations capabilities to consume AMQP 1.0 messages, an open source component, Swift MQ client, was decided on to help development of the AMQP 1.0 client listener.
- For each message received, the listener application code will call a corresponding REST API made available by the vendor to enrich the data and forward it on to a new Enterprise API (Financial Ingestion Service) that handles the ingestion and routing of the data.
- Real time integration using the Transactional Outbox microservices design pattern with the expectation the messages are idempotent – meaning that duplicates may occur and the downstream systems must support this possibility and handle accordingly.
- The Financial Ingestion Service API will take the data it has received to the following 1) Store the full message into a landing zone database table in JSON format with an organizationally defined JSON schema, 2) Store the message identifier of the full message into a “transaction outbox” database table. If both of those operations succeed, the API will return a 200-OK response to the client. Otherwise, a failure status code will be returned.
- Upon success or failure, the listener will have the original event message removed and successfully processed or moved to a dead-letter queue and provide a notification to the IT support team
- Data Processing and Integration to Target Applications
- We’ve created a data pipeline that ingests data into from the vendor’s SaaS application into the organization eco-system in real time, and we have provided a real time event based architecture to consume that data and push it into the target systems. This sets the standard in the organization for the real time event based architecture to be used by all future real time integrations.
- Great Plains: The existing API provided by Microsoft for Great Plains is not a RESTful API and is using a SOAP based XML interface. The decision is made to build a new REST API as a proxy to be used within the API ecosystem for standard integration to and from Great Plains to be used for this solution and future solutions.
- PeopleSoft Financials: New tables for ingestion of the data to ingest invoices, payments, and line items; new scripts for ingesting the data into PeopleSoft Financials from the new tables. A new PeopleSoft Financials Business Service will sit in front of these tables to orchestrate the communication into the tables.
- Category Code to GL Account Mapping
- An enterprise grade DRM (Data Reference Management) platform is already being procured by the organization as part of another initiative, however, the DRM solution will not be ready by the time the organization needs to go live with the new features in this solution for payments and invoices.
- A DRM solution is the perfect solution companion to hold the reference mappings between the “Target Financial System”, “Vendor Category”, and “GL Account”.
- Since the DRM component will not be ready by the time we need it, an interim solution will have this data maintained in a maintainable data table exposed via a new “Reference Data Service API” that will provide this data to our integration for ingestion into the financial systems. The data will be maintained by the technology support team according to the needs of the business.
- The future state architecture will have the data migrated to the new DRM platform that will allow the business teams to maintain their reference data directly. The “Reference Data Service API” will continue to be used and will be re-worked to use the DRM platform as the data source. This allows us to easily migrate from interim to target state with an easy transition as possible.
- Event Based Architecture – Consumption of Landing Zone Data
- We will create a monitoring process that monitors for events at a 10 second interval. The purpose of this monitoring process is to monitor the transactional outbox for new events. It will query the transactional outbox table looking for new records, and add them to a message queue. This is part of a standard micro services design pattern.
- Two new listeners will be developed; one of them is to process PeopleSoft messages and the other is to process messages intended to be sent to Microsoft Great Plains.
- Each of these listeners will subscribe to only the messages intended for it’s target system.
- Each of them will consume the Reference Data Service API to get the proper GL account before sending the data to the target system.
- The messaging technology for the event based architecture will be based on Rabbit MQ, but it will use AMQP 0.9+ instead of AMQP 1.0 (the vendor is using AMQP 1.0, however, as described above). (AMQP 1.0 is a standard and it was important for the vendor to use this standard for two-way integration – AMQP 1.0 is used natively by messaging components on major cloud platforms such as AWS and Azure. The AMQP 1.0 standard leaves a lot to be desired however and it does not describe any standard for publisher subscriber messaging although it is achievable. Internally, within the organization, an evaluation was done and design decisions made to use AMQP 0.9+ with Rabbit MQ instead of am AMQP 1.0 implementation. This is documented and the technical direction has been set. )
With these facts and corresponding requirements and justification, we now have the basis that will form the core logical solution architecture.
Note, that for the purpose of this document, these steps were described in a sequential order, but in reality it is a continual negotiation and I typically keep a living high level solution architecture logical diagram that is updated as things change and as new facts are attained. Let’s take a look at the high level solution architecture for future state and the long term vision defined as a result of the decisions made and facts that have be attained.
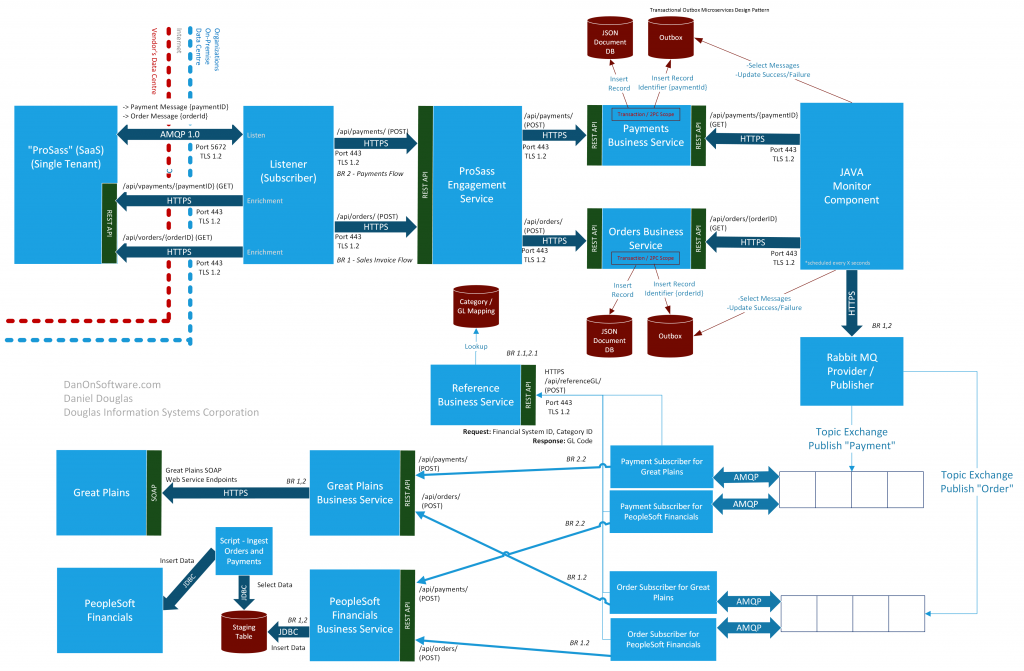
The logical diagram creates a detailed technical view of the solution architecture which is usually followed by physical architecture views which hone in on infrastructure and networking technical depictions. On the logical diagram, the business requirements pertaining to the solution are clearly marked with an overlay as per the example above, and this is a suitable and appropriate overlay for a logical architecture view of a solution when looking it it through the context of the solution. However, as the organization expands and systems broaden their scope, some of these systems that are identified to be in scope of this solution will become part of the scope of different solutions with each having their own logical solution architecture mapped to their corresponding business requirements, and there may be system or integration architectures created and maintained that highlight all of the interactions with other systems that are part of other solutions.
Overlaying the high level business requirements on the solution architecture itself ensures we have traceability back to the original requirements and ultimately to the user stories (assuming they are used) that the development team will base their development off of. This is one way, but not the only way to trace architecture back to requirements; a separate document or textual depiction of the mapping is also suitable. It’s important to maintain traceability from the user story itself back to the original business requirement and from the business requirement to the solution architecture. The architecture does not drive development, the user stories should, and those user stories get aligned to business requirements and architecture. Solution architecture can help identify core technical scaffolding that needs to be implemented, but the architecture itself is not the driver of the development although it can be used to determine future infrastructure and other physical requirements that are required as part of the scope of the solution. (‘User stories’ nomenclature was used here assuming an Agile development methodology based on user stories, but replace user story nomenclature with any artifact coming out of business analysis that describes the piece of work or functionality needed to be built)
The architecture can be summed up quite easily as being the result of significant decisions that have been made on the basis of the business requirements and facts collected, and thus all of the facts and clarifications collected should be documented and traceable to each impacted decision. This helps the architect and related project team to be confident that the right decisions are being made, provides ample justification for the reasons for the decisions, and can be used as evidence to support your position when justifying the decisions to sponsors and stakeholders.
This article has focused on creating conceptual and logical views of solution architecture, but I intentionally left out other architecture artifacts, including physical architecture, integration architecture, sequence diagrams, security models, user interaction, software architecture, and others. There are many types of documentation that are suitable for any particular solution, however, as a senior leader and technical expert, the architect must use good judgement to determine the documentation, team sessions and deep dives, work, and level of detail of that work that is needed. The reality of solution architecture and as a solution architect consultant is that it is 100% critical to own your methodology and level set and deliver according to expectations; this means identifying at every point in the process where it’s best to deploy your effort and energy and not wasting time creating unnecessary artifacts if they are not warranted, and focus on what is important to deliver serious business value knowing that some clients may expect certain deliverables as a hand-off that are contractual deliverables, and thus those become required as well. (See related article: Refining and Applying Methodology and Rules of Engagement at the Onset of New IT Consulting (B2B) Projects)
As a solution architect, how do you know what exactly is required, and the level of detail required for any given solution? Well, no one tells you and no one can tell you. If someone has to tell you, then you either still have a lot to learn or the person telling you doesn’t understand solution architecture and what it’s real value is – in this case it’s important to push back a little bit and educate about the solution architecture deliverables and what is really required and what isn’t.
As an example, a very complex integration that requires very specific things to occur in the correct sequence in order for the solution to even work should be documented and the technical and strategic direction of that needs to be set by the architect. This does not mean that the solution architect should spend any time whatsoever documenting the sequence of other business functionality that is not critical to the significant decisions dictated by the solution architecture. If something can be relatively easily figured out by the development team or systems analysts, then that’s where the responsibility should be, but the architect is responsible to convey all details of the significant aspects of the architecture that need to be taken into account. Another example could be in describing an event driven integration when the team is not familiar with event driven architecture, message queues, topics, and publisher/subscriber patterns. Some teams will instinctively “get it” because they have done it before, and others may have very limited exposure to these concepts. In the case of the latter, much more detail is warranted to ensure that there is enough detail and knowledge sharing to ensure the development and implementation teams understand precisely how the mechanisms works, and this should also go hand in hand with orchestrating developer walk-throughs, demos, and even training sessions to ensure that the team “get’s it”. After all, it’s the responsibility of the solution architect to ensure that the team “get’s it” and are aligned to the vision, and it is one of the core reasons architects are necessary. If the team doesn’t “get it” or understand it, then the responsibility is on the architect and not the team, so deliverables include ensuring a common shared vision and common understanding.
Thank you for linking to my article at danonsoftware.com