
The command and query responsibility segregation (CQRS) pattern is a pattern that can be deployed as part of microservices and other architectures.
This pattern is often overlooked by architects and development teams even though it is a well documented pattern. Even though some architects may not even know about or understand this pattern, there are reasons not to use it, and a few reasons to use it.
CQRS is a data access and performance optimization pattern that has specialized use cases. It’s usage can be complex and the decision to use the pattern shouldn’t be taken lightly. The biggest reason to use this pattern is to meet performance objectives. Implementing this pattern adds complexity to development and design, and therefore it is not necessarily the foremost pattern to use in order to meet performance objectives.
From simply a data pattern perspective, there are lots of simpler approaches that work well. For example, different models for consumption and persistence can easily be abstracted into a software layer that sits above your data storage such as in a microservice or engagement/experience API layer, or the data can be ingested into a data mart or reporting table to facilitate “view” access to the data for specific reporting and analytics scenarios.
So, why actually use it?
The idea around CQRS is that you have a different data model or data repository for persistence of data than from consumption of data. One repository handles “commands” (persistence) and the other model handles “query” (consumption).
I’ve seen CQRS described in different ways:
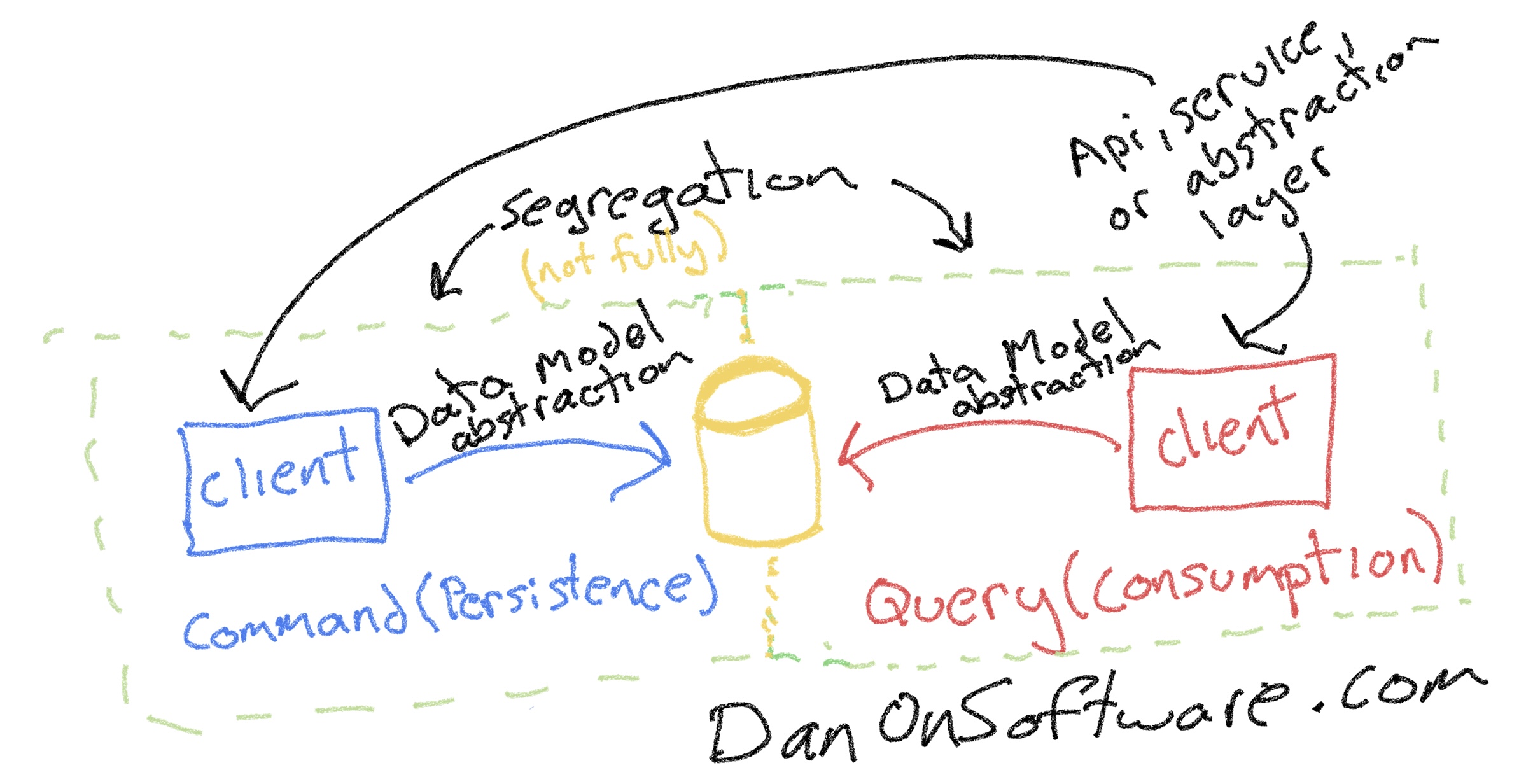
- CQRS means having different data models for persistence and consumption that share the same backend repository — meaning that the data storage repository is the same, but the software models that represent the data storage are different. (See diagram below)
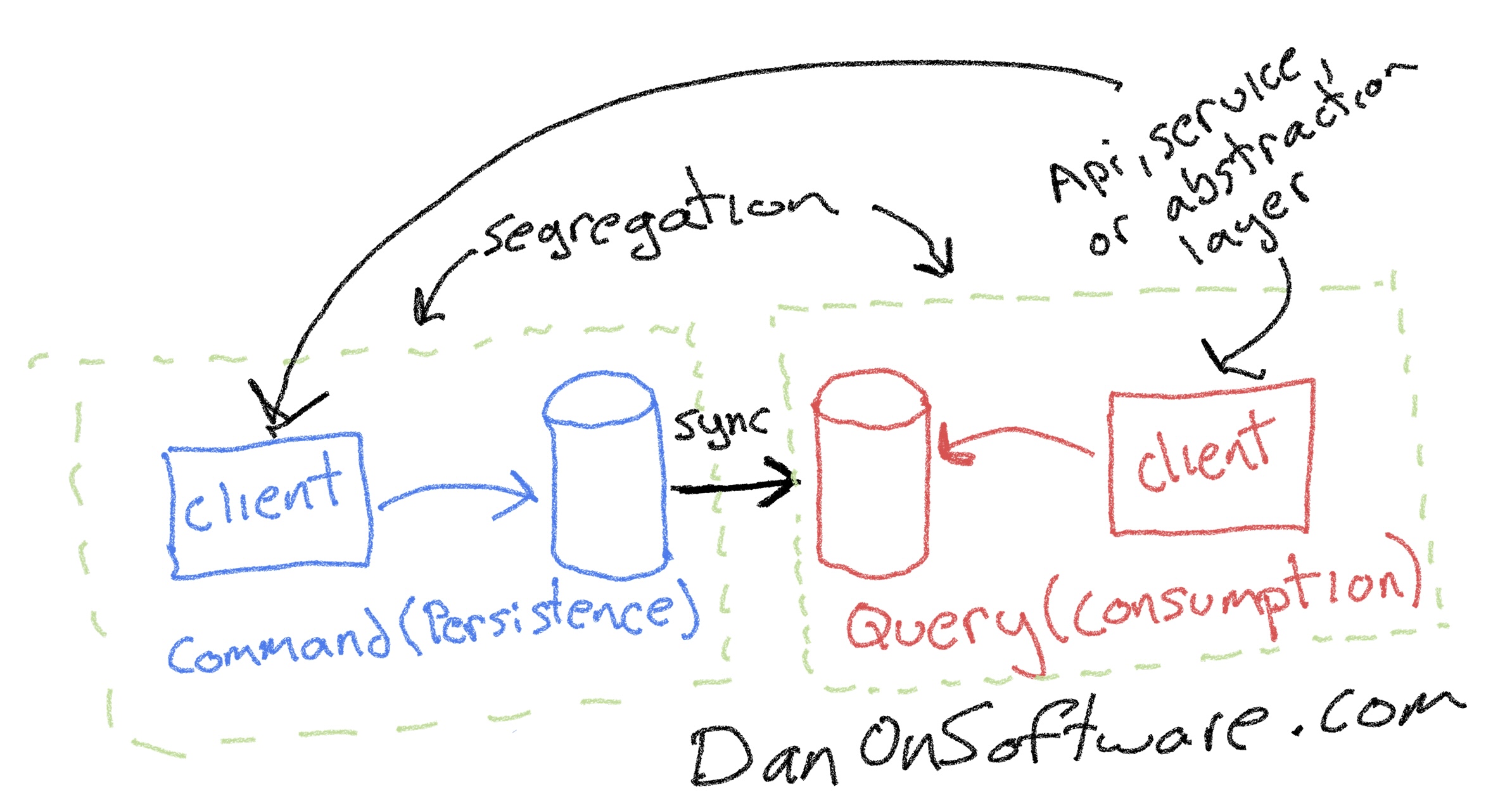
- CQRS means having different backend data repositories with different structures for consumption than for persistence — this would naturally facilitate having different software modes that represent the underlying data as the underlying repositories would be structured differently. (See diagram below)
My take is that if the data repository is the same for consumption and persistence then it is not truly segregated and although some people may call it CQRS, I’d prefer to refer to that as more of a “poor person’s CQRS”. Yes, the processing could be segregated with different abstraction layers on top of it, but the underlying data repository is the same which limits what we can do to meet the core performance based uses cases that make CQRS more viable.
If the underlying data repository is the same for consumption and persistence then any different software data models are just a facade or adaptation on a base data model. Since there are so many easy ways to segregate consumption and persistence at the software or even protocol layer, there isn’t anything special or complex there. A Layer 7 Load Balancer or API Gateway could just as easily segregate consumption and persistence requests to different sets of scaled out microservices.
Conversely, when we actually segregate the backend data models we are truly entering the more complex realm of CQRS.
What does CQRS entail?
We can develop the repositories differently and thus the software data models and processing code can be developed independently from each other. We can fine tune the software layers such as on the APIs that access the backend repositories and add fine performance tuning on the hardware and database repositories independently.
This means we can fine tune the data models for consumption and persistence differently and model each according to the use cases or scenarios for each. This in-turn could lead to less business processing in the software layers for consumption and persistence operations further increasing performance. Additionally, at the data repository hardware layer, different performance approaches can be employed such as indexing and partitioning which will impact performance on the consumption side independently from the persistence side.
CQRS can be useful in certain situations, including:
- Significant lead time when retrieving or persisting data that cannot be optimized to the degree required or the cost to optimize it is too great
- Significantly different usage for reading and writing data or significantly different load and scale requirements for the two
It’s a tricky pattern. We run into complexity because we will be dealing with different data models at the physical data repository level. Since the data model for consumption is physically different than the data model for persistence, you run into the following elements of complexity:
- Extensive data mapping and validation required to support the two models
- Settle for ‘eventually consistency’ between the data repositories in most scenarios and requires lead time to implement consistency between data stores
- Real time consistency (or near real time) is possible with events, queues, or other synchronization but requires careful consideration, planning, and development to get it right
- Additional lead time for development and testing
- Data models could get out of sync without additional processes to validate data fidelity
I recommend first looking at other approaches and patterns and only considering CQRS in very specialized scenarios. Often performance objectives can be met by increasing scale on the underlaying hardware, developing systems that allow you to scale up and scale out, reducing complex logic, writing higher performing code, and optimizing data storage with indexing and partitioning. There are logistical advantages to keeping a single data model for reading and writing.
I’ve seen some advocates for CQRS indicate that one of the advantages of CQRS is segregating development, so that you can have different development teams work on data consumption and data persistence. I don’t buy it. Yes, although technically there is some truth there, I do not see it as a significant advantage over other approaches that achieve the same objective without CQRS. Once you have your single data model, abstracting the consumption coding from persistence coding can be done on the same model fairly easily which can lead to different teams working on different parts of the equation without CQRS. I wouldn’t recommend considering CQRS if your reasoning is simply to segregate the development to different teams.